本地使用OLLAMA搭建大模型
本地使用OLLAMA搭建大模型
什么是大模型
大模型(Large Model)通常指的是由大量参数组成的机器学习模型,特别是在自然语言处理(NLP)领域,通常指的是基于深度学习的神经网络模型,如GPT(Generative Pre-trained Transformer)系列。以下是大模型的一些关键特点和内容:
特点
大量参数:大模型通常包含数亿到数千亿个参数。这些参数通过大规模的数据集训练,使模型能够捕捉和生成复杂的语言模式和结构。
强大的语言理解和生成能力:大模型在处理各种语言任务时表现出色,如文本生成、翻译、摘要、问答等。
预训练和微调:大模型一般先通过海量文本数据进行预训练,学习广泛的语言知识和模式,然后通过微调(fine-tuning)在特定任务或领域数据上进一步优化。
多功能性:大模型可以用于多种任务,不需要为每个任务单独训练一个新模型,只需通过调整提示词或微调即可适应新任务。
发展历程
早期模型:早期的语言模型,如Word2Vec和GloVe,主要关注词向量的表示。
Transformer架构:Transformer模型的引入是一个重大突破。它利用自注意力机制,能够更好地捕捉文本中的长距离依赖关系。
GPT系列:
- GPT-1:OpenAI发布的第一个GPT模型,展示了通过预训练和微调进行文本生成的潜力。
- GPT-2:扩展了模型的规模和训练数据量,显著提升了生成文本的质量。
- GPT-3:包含1750亿个参数,大幅提升了模型的生成能力和多功能性。
- GPT-4:进一步扩展了参数规模和训练数据,增强了模型在多任务处理中的表现。
应用领域
自然语言处理:文本生成、翻译、摘要、情感分析等。
对话系统:聊天机器人、虚拟助手、客户服务等。
创意写作:文章、故事、剧本生成等。
教育和研究:提供知识问答、辅助写作、语言学习等。
商业和营销:文案撰写、个性化推荐、数据分析等。
挑战和问题
计算资源需求:大模型的训练和推理需要大量的计算资源和时间。
数据隐私和安全:使用大规模数据进行训练可能涉及隐私和数据安全问题。
模型偏见:训练数据中的偏见可能导致模型输出结果中存在偏见。
可解释性:大模型的决策过程复杂,难以解释其生成的具体原因和逻辑。
未来发展
模型压缩和优化:研究如何在保持性能的前提下降低模型规模和计算需求。
更好的训练数据和方法:提高数据质量,改进训练方法,减少偏见和提高模型的鲁棒性。
多模态模型:结合文本、图像、音频等多种数据类型,提升模型的综合理解和生成能力。
通过了解大模型的特点、应用和挑战,可以更好地利用这些先进的技术,实现各种实际应用中的创新和改进。
使用 OLLAMA 搭建大模型
环境准备
- 有一台性能不差的电脑,OLLAMA 推荐配置如下,至少需要 8G 的 RAM:
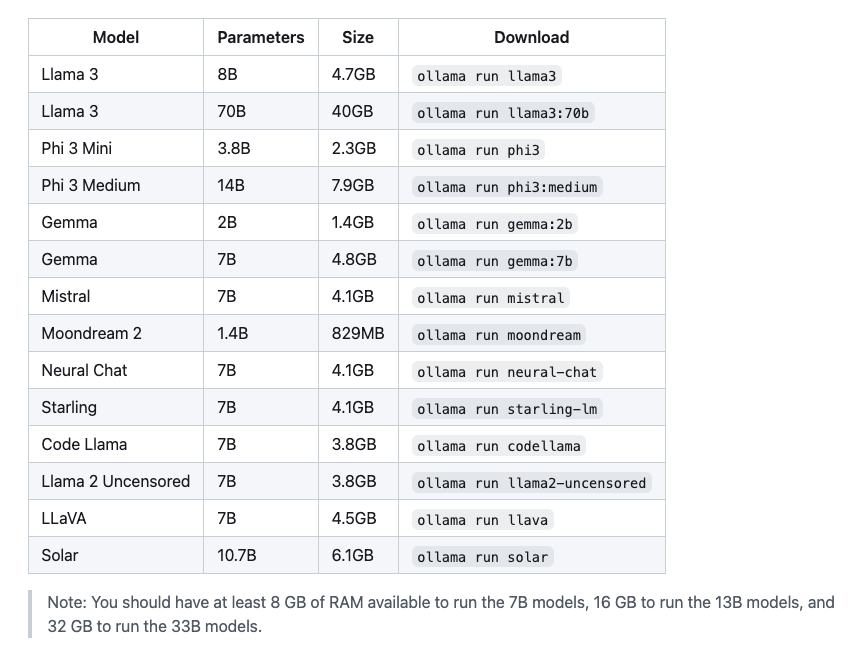
- 准备 docker 环境,可参考教程 docker基本使用;
搭建 OLLAMA
https://ollama.com
https://hub.docker.com/r/ollama/ollama
使用 docker 安装 OLLAMA
docker run -d -v ~/.ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
Unable to find image 'ollama/ollama:latest' locally
latest: Pulling from ollama/ollama
a8b1c5f80c2d: Pull complete
7110e83425ad: Pull complete
d73d7155397d: Pull complete
Digest: sha256:6363c5da064b02b5a1d15dbd1205c652e01c0e57accbfd831115e35a3efe0572
Status: Downloaded newer image for ollama/ollama:latest
8eb905b0e7b0bba918095d2c5eed669bda3b9d67ac947c77eef18ceae475ed0f
因为基础模型镜像比较大,所以建议使用挂载卷的方式将 OLLAMA 下载的模型挂载到宿主机的~/.ollama目录下,这样后面多次折腾下载数据会快一些。
启动完成之后,可以在浏览器打开http://127.0.0.1:11434,或者在终端输入
curl http://127.0.0.1:11434
Ollama is running
可以看到 OLLAMA 启动成功了。
也可以查看本机的局域网 IP 是多少,方便后面部署 Open-WebUI 使用。
ifconfig|grep 192
inet 192.168.1.3 netmask 0xffffff00 broadcast 192.168.1.255
inet 192.168.31.62 netmask 0xffffff00 broadcast 192.168.31.255
inet 192.168.64.1 netmask 0xffffff00 broadcast 192.168.64.255
curl http://192.168.1.3:11434
Ollama is running
运行大模型
进入 Docker 容器内部
docker exec -it ollama bash
打开 ollama 网站搜索需要运行的大模型,我们已 llama3 为例,进行下载。
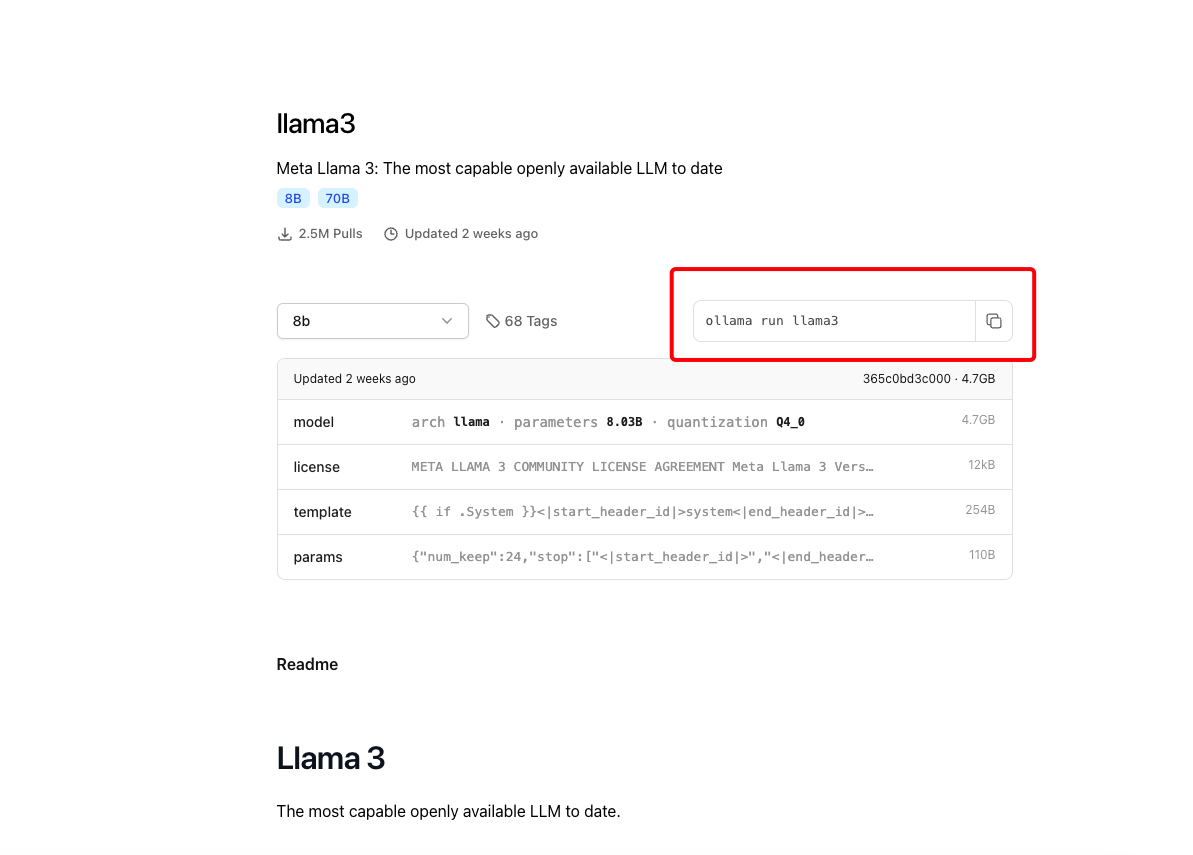
复制命令ollama run llama3,也可以根据配置下载不同参数的大模型。
下载过程需要一些时间,毕竟文件还是挺大的,大模型参数越大,镜像越大。
ollama run llama3
pulling manifest
pulling 6a0746a1ec1a... 100% ▕██████████████████████████████████████████████████████████▏ 4.7 GB
pulling 4fa551d4f938... 100% ▕██████████████████████████████████████████████████████████▏ 12 KB
pulling 8ab4849b038c... 100% ▕██████████████████████████████████████████████████████████▏ 254 B
pulling 577073ffcc6c... 100% ▕██████████████████████████████████████████████████████████▏ 110 B
pulling 3f8eb4da87fa... 100% ▕██████████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
success
>>> Send a message (/? for help)
此时就可以和 llama3 聊天了。
>>> 你是谁
I am LLaMA, an AI assistant developed by Meta AI that can understand and respond to human input in a conversational
manner. I'm not a human, but a computer program designed to simulate conversation and answer questions to the best
of my ability based on my training data. I can generate human-like text responses to your questions or prompts, and
engage in natural-sounding conversations. My primary function is to assist users with information and tasks, and to
provide helpful and accurate responses. I'm constantly learning and improving, so please bear with me if I make any
mistakes or don't fully understand what you're asking. 😊
>>> 可以用中文和我聊天吗
😊
可以!我也能使用中文与你聊天。请随时提出你的问题或想法,我将尽力回答和讨论。
(Note: Although I'm capable of understanding and responding in Chinese, my proficiency may vary depending on the
complexity and nuance of the topic. If you're unsure about something or want me to clarify a point, please don't
hesitate to ask!)
可以看到,llama3 对中文并不是很熟悉,有兴趣的同学可以使用阿里巴巴开源的千问2大模型(qwen2)。
搭建 Open-WebUI
在终端执行命令
docker run -d -p 3000:8080 -v ~/.open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
128ae8d335f61476d51f40d1f3bc88e9ae2b136cfd7a5fae0e42412e254f7f3c
浏览器打开http://localhost:3000,会进入登录界面,此时需要注册一个账号,第一个注册的账号是管理员账号。
看下提问面板

搭建 MaxKB
MaxKB 是一款基于 LLM 大语言模型的知识库问答系统。MaxKB = Max Knowledge Base,旨在成为企业的最强大脑。
开箱即用:支持直接上传文档、自动爬取在线文档,支持文本自动拆分、向量化、RAG(检索增强生成),智能问答交互体验好;
无缝嵌入:支持零编码快速嵌入到第三方业务系统;
多模型支持:支持对接主流的大模型,包括 Ollama 本地私有大模型(如 Meta Llama 3、qwen 等)、通义千问、OpenAI、Azure OpenAI、Kimi、智谱 AI、讯飞星火和百度千帆大模型等。
docker run -d --name=maxkb -p 8081:8080 -v ~/.maxkb:/var/lib/postgresql/data 1panel/maxkb