Appearance
一篇文章搞懂 Redis 从面试到应用
一篇文章搞懂 Redis 从面试到应用
Redis 基础
Redis 是一个开源的内存结构存储系统。可作于数据库、缓存和消息中间件等。
数据类型
| 数据类型 | 说明 |
|---|---|
| String | 字符串 |
| Hash | 散列,相当于 Java 中的 Map |
| List | 列表 |
| Set | 集合。Set 本质是一个特殊的 Hash,他的 Value 为空 |
| ZSet | 有序集合 |
| BitMap | 本质是 String,因为 String 最大长度是 512M,所以BitMap最多可存储2^32个bit |
单机搭建
下载 tar 包到 /opt 目录下并安装。
wget https://download.redis.io/releases/redis-5.0.5.tar.gz tar xzf redis-5.0.5.tar.gz mv redis-5.0.5 redis cd redis/ make install此时 redis 已经安装好了,可以查看。
$ ls /usr/local/bin/redis-*可以看到一些执行文件
/usr/local/bin/redis-benchmark /usr/local/bin/redis-check-rdb /usr/local/bin/redis-sentinel /usr/local/bin/redis-check-aof /usr/local/bin/redis-cli /usr/local/bin/redis-server创建工作空间并复制配置文件。
mkdir -p /redis/singleton & cp /opt/redis/redis.conf /redis/singleton/修改配置文件。
# 改为内网ip,连接时可以通过外网连接 bind 10.255.0.xxx # 设置密码 requirepass jonkee # 以守护进程启动 daemonize yes # 日志文件 logfile "/redis/singleton/redis.log"启动 redis。
/usr/local/bin/redis-server redis.conf启动完成,可以通过命令行客户端连接,也可以用其它客户端通过外网连接。
/usr/local/bin/redis-cli -h 10.255.0.xxx -a jonkee测试命令和执行结果如下:
10.255.0.111:6379> set name muan OK 10.255.0.111:6379> get name "muan"
客户端
- 通过 redis-cli 连接。
- 其它第三方客户端如 jedis 等。
- 可视化 GUI 推荐 AnotherRedisDesktopManager,主要是好看。还有 rdm 或者 medis 可以选择,实在都不喜欢可以去 github 找一下喜欢的。
持久化方案
RDB(Redis Database)
每间隔一段时间生成一个快照。该时间段可配置。快照生成后会覆盖之前的快照,所以只有一个快照文件,生成的过程中会有一个临时文件。这种持久化方案是 Redis 默认的方案。优点是恢复快,缺点是可能损失的数据会大。
手动使用主进程执行 RDB 备份的命令save。该命令会阻塞。
手动开启其它进程执行 RDB 备份的命令bgsave。该命令不会阻塞。
redis> save
OK
redis> bgsave
Background saving started可配置 rdb 文件的位置和名字。默认是在执行开启 redis-server 的当前目录,文件名是dump.rdb。建议将dir写死成固定目录。
dir ./
dbfilename dump.rdb定时生成 RDB 文件的时间可以配置。如下配置表示三个条件,满足其一就执行一次备份。如果关闭 RDB 功能,则无需配置该选项。
# 900s 内有1次数据更改
save 900 1
# 300s 内有10次数据更改
save 300 10
# 60s 内有10000次数据更改
save 60 10000AOF(Append Only File)
系统记录每一个进程插入或修改的日志,文件会一直增加。优点是恢复慢,由于是同步新增日志,所以损失可以忽略不计。
开启 AOF 只需配置appendonly yes,此时在之前配置的dir目录下回出现一个appendonly.aof文件。
appendonly yes
appendfilename "appendonly.aof"触发机制。
# no:表示等操作系统进行数据缓存同步到磁盘(快,持久化没保证)
# always:同步持久化,每次发生数据变更时,立即记录到磁盘(慢,安全)
# everysec:表示每秒同步一次(默认值,很快,但可能会丢失一秒以内的数据)
appendfsync everysec混合持久化
混合持久化吸收了 RDB 和 AOF 两种方式的优点。当 AOF 文件达到一定条件时,redis 会开启一个新的子进程来对 AOF 文件进行重写,比如set name jonkee和del name这两条命令的 AOF 记录就可以清除掉。清除掉之后生成的其实是 RDB 格式的文件,然后将该文件写入 AOF 文件中,此时 AOF 文件中就会存在一部分 RDB 格式的和一部分 AOF 格式的,这样恢复的速度能得到很大提高,也能保证数据最少丢失。
# 开启混合持久化
aof-use-rdb-preamble yes
#当AOF文件大小的增长率大于该配置项时自动开启重写。
auto-aof-rewrite-percentage 100
#当AOF文件大小大于该配置项时自动开启重写
auto-aof-rewrite-min-size 5gb缓存穿透、击穿、雪崩
缓存穿透
缓存穿透就是穿过缓存进入数据库。正常来说使用缓存的流程是这样的。
- 根据一个 key 从缓存中获取数据。
- 获取到数据就返回。没有获取到数据,则从数据库中获取数据。
- 获取到数据就将数据放入缓存,然后返回,没有则直接返回。
如果知道一个肯定不存在的数据的 key,数据库没有,缓存中也没有,请求就会访问数据库。如果恶意攻击的话,会导致数据库压力过大。
解决方案:
- 如果一个 key 没有值得话,可以将这个 null 值存到缓存中,设置一个过期时间。
- 接口层增加拦截校验,如布隆过滤器。
缓存击穿
缓存击穿是指从一个点击穿缓存,进入数据库。缓存击穿是对热点数据进行高频率访问的时候,该缓存突然过期或一开始没有该缓存,导致所有的请求集中在一点进入了数据库。
解决方案:
- 设置热点数据永远不过期。
- 布隆过滤器。
- 接口限流与熔断,降级。
- 加互斥锁。
缓存雪崩
缓存雪崩是指在某个时间段内,缓存集中过期失效。
解决方案:
- 过期时间不要太集中,给范围随机。
- 热点数据永不过期。
- 保证机器高可用。
集群模式
主从复制
分为一个 master 节点和多个 slave 节点,slave 节点从 master 同步数据。可实现读写分离,由 master 写,从 slave 读。当 mastere 节点故障之后,slave 节点可以接替成为 master 节点提供服务,但是该操作需要人工完成。
replica <masterip> <masterport>主从复制原理
当 slave 连接到 master 之后,发送一个 PSYNC 命令到 master,master 此时 fork 出一个子进程执行 bgsave 命令生成 rdb 文件,在生成发送 rdb 文件期间,如果有新的增删改命令执行,master 会创建一个缓冲区记录这些命令,等生成的 rdb 文件发送到 slave 之后,会将缓冲区里的命令同步给 slave 执行。
全量同步流程如下: 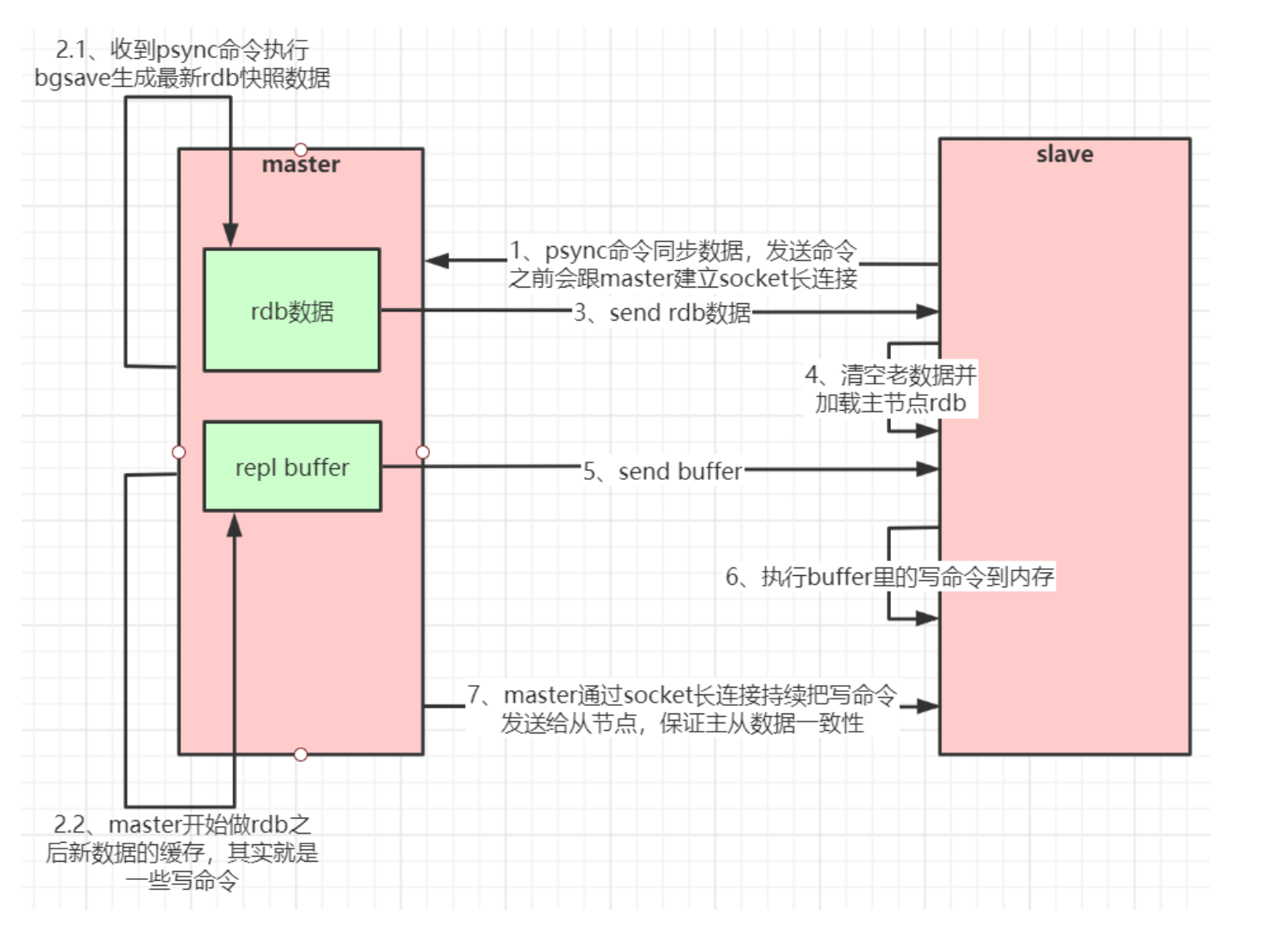 主从复制也支持增量同步。如果 slave 在短时间内与 master 断开连接,可以发送带有偏移量的 PSYNC 命令进行增量同步。master 会在其内存中创建一个复制数据用的缓存队列,缓存最近一段时间的数据,maste r和它所有的 slave 都维护了复制的数据下标 offset 和 master 的进程 id,因此,当网络连接断开后,slave 会请求 master 继续进行未完成的复制,从所记录的数据下标开始。如果 master 进程 id 变化了,或者从节点数据下标 offset 太旧,已经不在 master 的缓存队列里了,那么将会进行一次全量数据的复制。 增量同步流程如下:
主从复制也支持增量同步。如果 slave 在短时间内与 master 断开连接,可以发送带有偏移量的 PSYNC 命令进行增量同步。master 会在其内存中创建一个复制数据用的缓存队列,缓存最近一段时间的数据,maste r和它所有的 slave 都维护了复制的数据下标 offset 和 master 的进程 id,因此,当网络连接断开后,slave 会请求 master 继续进行未完成的复制,从所记录的数据下标开始。如果 master 进程 id 变化了,或者从节点数据下标 offset 太旧,已经不在 master 的缓存队列里了,那么将会进行一次全量数据的复制。 增量同步流程如下: 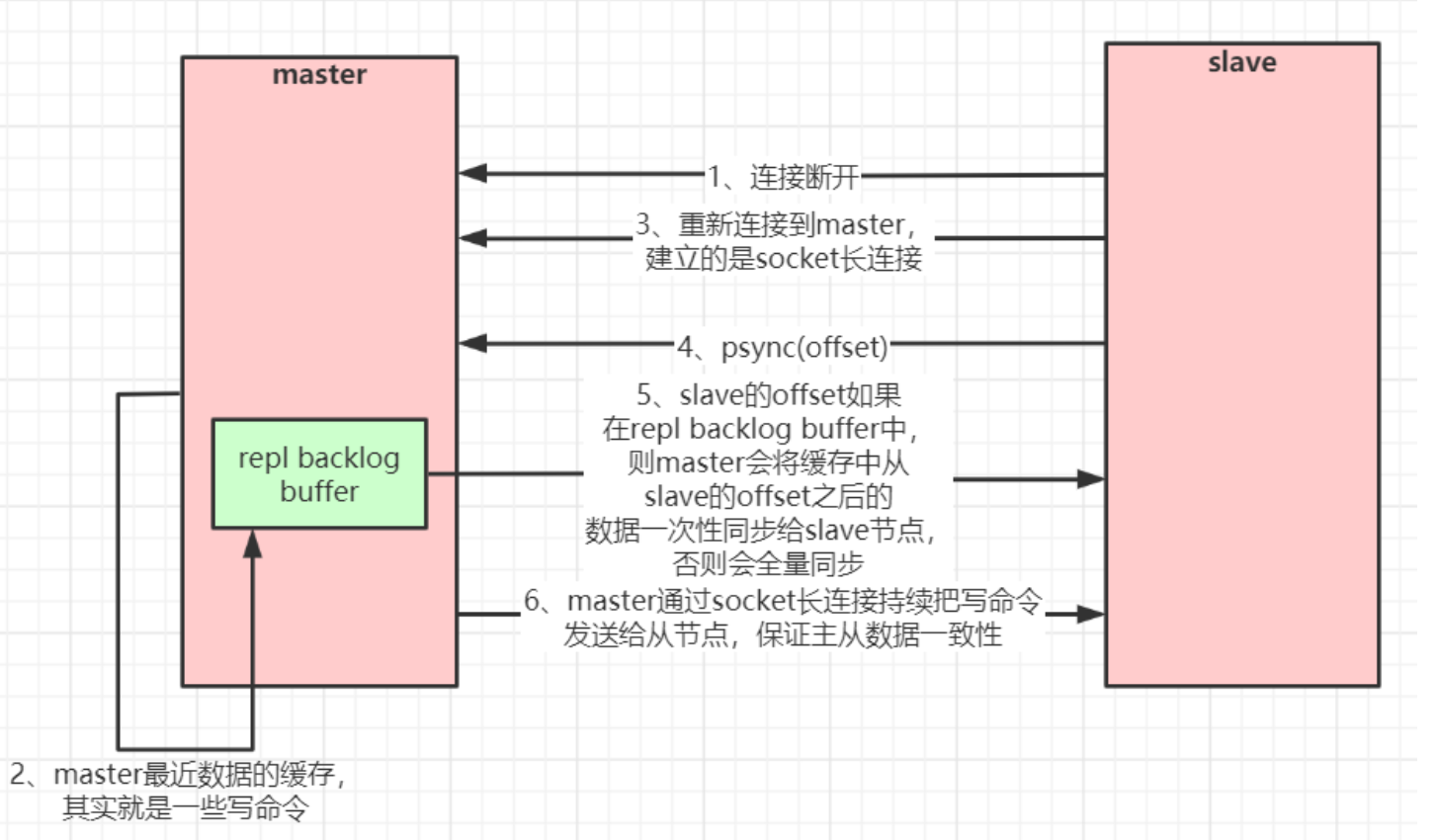
哨兵模式
哨兵模式是基于主从复制模式的,在此基础上多了一个哨兵的角色,哨兵可以监控 master 和 slave 的状态,在 master 出现问题时,能够从 slave 中选取一个节点作为新的 master 来保证系统正常工作。
原理:心跳机制加投票裁决。每个哨兵会定时向其它哨兵、master 和 slave 发送心跳,确保对方还活着,当多数哨兵报告某个 master 已经宕机之后,系统会投票从 slave 中选出新的 master。
cluster 模式
cluster 集群模式本质上是多个主从复制模式的集合,即一个 cluster 集群包括3个以上的主从复制小集群。cluster 集群引入了哈希槽的概念,Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽。集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
- 节点 A 包含 0 到 5500号哈希槽.
- 节点 B 包含5501 到 11000 号哈希槽.
- 节点 C 包含11001 到 16384号哈希槽.
cluster 搭建实战
搭建一个 cluster 集群,包括三个 master-slave 集群,即总共需要6个节点。因为在同一台机器上搭建,所以用端口号区分,端口从6000-6005。
创建工作空间。
mkdir /redis/cluster & cd /redis/cluster mkdir 6000 & cp /opt/redis/redis.conf /redis/cluster/6000/修改配置文件。
bind 10.255.0.223 port 6000 daemonize yes pidfile /redis/cluster/6000/redis_6000.pid logfile "/redis/cluster/6000/redis.log" dir /redis/cluster/6000/ cluster-enabled yes cluster-config-file nodes-6000.conf requirepass jonkee masterauth jonkee将其它节点的配置文件做同样的更改。
mkdir 6001 & mkdir 6002 & mkdir 6003 & mkdir 6004 & mkdir 6005 # 替换配置文件中的端口号,输出到新的配置文件中 sed 's/6000/6001/g' 6000/redis.conf > 6001/redis.conf启动所有 redis,启动之后查看 redis 进程,可以见到一个 [cluster] 标记,但是此时的六个节点都是相互独立的。
/usr/local/bin/redis-server 6000/redis.conf ps -ef|grep redisredis 进程如下:
root 547 1 0 22:26 ? 00:00:00 /usr/local/bin/redis-server 10.255.0.223:6001 [cluster] root 755 1 0 22:26 ? 00:00:00 /usr/local/bin/redis-server 10.255.0.223:6002 [cluster] root 976 1 0 22:26 ? 00:00:00 /usr/local/bin/redis-server 10.255.0.223:6003 [cluster] root 1142 1 0 22:26 ? 00:00:00 /usr/local/bin/redis-server 10.255.0.223:6004 [cluster] root 1399 1 0 22:26 ? 00:00:00 /usr/local/bin/redis-server 10.255.0.223:6005 [cluster] root 30666 1 0 22:25 ? 00:00:00 /usr/local/bin/redis-server 10.255.0.223:6000 [cluster]搭建集群及分配哈希槽。搭建过程中会输出主从信息和分配的哈希槽信息,输入 yes 确认。可以看到6000、6001和6002是 master 节点,哈希槽位分别是[0-5460]、[5461-10922]和[10923-16383],它们的 slave 节点是6005、6003和6004。注意,这里集群节点间的通信用的是内网 ip,如果要在外网使用会存在连接不上的问题,解决这个问题可以换成域名通信。
/usr/local/bin/redis-cli --cluster create \ 10.255.0.223:6000 10.255.0.223:6001 10.255.0.223:6002 \ 10.255.0.223:6003 10.255.0.223:6004 10.255.0.223:6005 \ --cluster-replicas 1执行成功后可以看到如下信息:
M: 4418f4dc304c9cdda79b63f7da3d66010080d2ea 10.255.0.223:6000 slots:[0-5460] (5461 slots) master M: da0dfdebf6c40967e907b401852339cc4e396030 10.255.0.223:6001 slots:[5461-10922] (5462 slots) master M: eb5c6796acdf0c5009e46493bac7d748429e552f 10.255.0.223:6002 slots:[10923-16383] (5461 slots) master S: f6d0043ba84adaaa1ee53d60df5c8ee6468fe1e3 10.255.0.223:6003 replicates da0dfdebf6c40967e907b401852339cc4e396030 S: cba8160ff71e9185a84466f535b0f517928b2789 10.255.0.223:6004 replicates eb5c6796acdf0c5009e46493bac7d748429e552f S: 2658465eac3c8bbd899816c6ac786e140bc4533e 10.255.0.223:6005 replicates 4418f4dc304c9cdda79b63f7da3d66010080d2ea Can I set the above configuration? (type 'yes' to accept): yes查看集群状态。
/usr/local/bin/redis-cli -h 10.255.0.223 -p 6002 -a jonkee cluster nodes结果如下:
2658465eac3c8bbd899816c6ac786e140bc4533e 10.255.0.223:6005@16005 slave 4418f4dc304c9cdda79b63f7da3d66010080d2ea 0 1587566606616 6 connected cba8160ff71e9185a84466f535b0f517928b2789 10.255.0.223:6004@16004 slave eb5c6796acdf0c5009e46493bac7d748429e552f 0 1587566601000 5 connected eb5c6796acdf0c5009e46493bac7d748429e552f 10.255.0.223:6002@16002 myself,master - 0 1587566604000 3 connected 10923-16383 da0dfdebf6c40967e907b401852339cc4e396030 10.255.0.223:6001@16001 master - 0 1587566605000 2 connected 5461-10922 f6d0043ba84adaaa1ee53d60df5c8ee6468fe1e3 10.255.0.223:6003@16003 slave da0dfdebf6c40967e907b401852339cc4e396030 0 1587566603000 4 connected 4418f4dc304c9cdda79b63f7da3d66010080d2ea 10.255.0.223:6000@16000 master - 0 1587566604611 1 connected 0-5460连接测试,任意连接一个节点即可,注意要加上 -c 表示以集群模式连接。当存入
key1时,计算出的哈希槽是 9189,落在 6001 节点上。$ /usr/local/bin/redis-cli -c -h 10.255.0.223 -p 6000 -a jonkee验证一把
10.255.0.223:6000> set key1 value1 -> Redirected to slot [9189] located at 10.255.0.223:6001 OK 10.255.0.223:6001> cluster keyslot key1 (integer) 9189
删除策略和淘汰策略
删除策略
Redis 删除策略指 Key 如果有过期时间,将会根据一些策略来对这些 key 进行删除。
惰性删除
当写入或读取到某个过期的 key 时,发现该 key 过期了,则删除。
定期删除
惰性过期无法删掉冷数据(长时间没有被读取,所以无法删除),此时要定期删除已经过期的 key。
定时删除
redis 在设置 key 的过期时间的时候回创建一个定时器,当过期时间到达时会触发该定时器来删除 key。这种做法是以 cpu 来节省内存。
淘汰策略
当内存超过设置的 maxMemory 时,则触发淘汰策略。
缓存淘汰算法有以下几种:
- volatile-lru:从已经设置过期时间的数据中选出最近最少使用的数据淘汰。
- volatile-ttl:从已经设置过期时间的数据中选出将要过期的数据淘汰。
- volatile-random:从已经设置过期时间的额数据中随机选出任意数据淘汰。
- volatile-lfu:从已设置过期时间的数据集挑选使用频率最低的数据淘汰。
- allkeys-lru:从所有数据中选出最近最少使用的数据淘汰。
- allkeys-lfu:从数据集中挑选使用频率最低的数据淘汰。
- allkeys-random:从所有数据中随机选出任意数据淘汰。
- no-enviction:禁止驱逐数据。
事务
事务操作演示。MULTI开启事务,EXEC提交事务,DISCARD回滚事务。
10.255.0.223:6379> MULTI
OK
10.255.0.223:6379> set k1 v1
QUEUED
10.255.0.223:6379> set k2 v2
QUEUED
10.255.0.223:6379> EXEC
1) OK
2) OK注意,如果中途出现异常,那么事务会自动回滚。如果中途没有异常而是在提交后异常,那么只有出现异常的命令会无效,其它命令依然有效。
场景实战
如何存储一个用户的信息
一个用户的信息有很多字段,如:
public class User {
int id;
String name;
boolean sex;
int age;
}此时可以用hash这种数据结构,也可以用string的mset和mget命令,如:
redis> mset user:1:name jonkee user:1:sex true user:1:age 26
OK
redis> mget user:1:name user:1:sex user:1:age
0 jonkee
1 true
2 26如何实现浏览量
可以使用incr原子命令对一个key的值进行加一。如果该 key 不存在则会初始为0,然后再进行加一。对应的减一操作是decr
redis> incr article:view:1
1
redis> incr article:view:1
2
redis> incr article:view:1
3分布式 id 如何生成
可以使用incrby命令生成id。每一台机器实例来 redis 中通过incrby userid 1000来获取id,就是说每次获取到1000个id,第二台机器来获取的时候就是从1000之后再获取1000个id,借助于 redis 的单线程特性生成分布式 id。
redis> incrby userid 1000
1000
redis> incrby userid 1000
2000设计一个购物车
一个用户有个购物车,一般有如下操作。
- 添加商品。
hset cart:{userid} {goodsid} 1 - 商品加1。
hincrby cart:{userid} {goodsid} 1 - 获取商品的总数。
hlen cart:{userid} - 获取所有的商品。
hgetall cart:{userid} - 删除商品。
hdel cart:{userid} {goodsid}
redis> hset cart:1 1001 1
1
redis> hset cart:1 1002 1
1
redis> hincrby cart:1 1001 1
2
redis> hlen cart:1
2
redis> hgetall cart:1
1001 2
1002 1
redis> hdel cart:1 1001
1
redis> hgetall cart:1
1002
1设计微信公众号推送信息列表
当某个公众号发了一条推送之后,会向所有订阅这个公众号的用户推送这条消息。将用户要接收的信息放到一个list中可以轻松实现该功能。
- 将消息放入订阅列表。
lpush submsg:{userid} {msgid} - 获取最新消息。
lrange submsg{userid} {start} {stop}
redis> lpush submsg:1 100
1
redis> lpush submsg:1 101
2
redis> lpush submsg:1 102
3
redis> lrange submsg:1 0 1
0 102
1 101设计抽奖活动
一个抽奖活动有一下几个步骤。
- 参与抽奖。
sadd activity:{id} {userid} - 查看所有用户。
smembers activity:{id} - 抽奖,两个名额。
srandmenbers activity:{id} 2或者spop activity:{id} 1
redis> sadd activity:1 100
1
redis> sadd activity:1 101
1
redis> sadd activity:1 102
1
redis> smembers activity:1
0 100
1 101
2 102
redis> srandmember activity:1 2
0 101
1 100点赞功能
点赞功能一般有如下操作。
- 点赞。
sadd like:{msgid} {userid} - 是否已经点过赞。
sismember like:{msgid} {userid} - 所有点赞的人。
smember - 取消点赞。
srem like:{msgid} {userid}
redis> sadd like:1 100
1
redis> sadd like:1 101
1
redis> sismember like:1 100
1
redis> sismember like:1 104
0
redis> smembers like:1
0 100
1 101
redis> srem like:1 100
1
redis> smembers like:1
0 101关注模型/认识的人功能
- A 关注了【B,C,D】
- B 关注了【A,C,D,E】
- C 关注了【B,E,F】
- 计算 A 和 B 共同关注的人(交集)。
sinter follow:A follow:B - 计算 A 关注的人是否也关注了 B,排除 B 自身,对其它人做
sismember操作。 - 计算 A 可能认识的人。因为 A 和 B 相互关注,B 关注的人 A 没有关注,但是 A 可能认识这些人。
sdiff follow:B follow:A
redis> sadd follow:A B C D
3
redis> sadd follow:B A C D E
4
redis> sadd follow:C B E F
3
redis> sinter follow:A follow:B
0 D
1 C
redis> sismember follow:C B
1
redis> sismember follow:D B
0
redis> sdiff follow:B follow:A
0 A
1 E其它问题
为什么网络模块采用单线程?
因为 Cpu 不是 Redis 的瓶颈,影响 Redis 性能的是内存和网络带宽,所以没有上下文切换的单线程能很容易实现。
哨兵模式需要注意什么?
至少需要三个哨兵,须奇数个。
如何用 Redis 实现分布式锁?需要注意什么?
加锁的必须使用 set(key,value,nx,ex),即如果 key 不存在,则加锁成功,否则加锁失败。要为 key 设置过期时间,避免由于网络问题或其它原因导致客户端没有成功释放锁导致其它客户端永远无法访问。
释放锁需要获取锁,然后判断该锁是不是当前客户端持有的锁,然后删除,三个动作必须是原子操作,所以要用 lua 脚本来写,脚本如下:
if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 endRDB 和 AOF 两种持久化方案共存时,数据以哪种方式为准?会存在数据丢失的问题吗?怎么解决?
RDB 和 AOP 同时开启时,会以 AOF 为准,如果 RDB 的文件比较新,那么 RDB 的数据会丢失。解决该问题可以在配置文件中先关闭 AOF,以 RDB 的方式启动,等加载完成之后用客户端执行
config set appendonly yes命令,这样可以生成最新的appendonly.aof文件,然后下次就可以在配置文件中开启 AOP 了。redis 为什么快?
- 完全基于内存。要么是数据在内存,要么是数据在硬盘,索引在内存。
- 数据结构简单。
- 网络模块单线程,减少了不必要的上下文切换和竞争,不用考虑各种锁的性能消耗。
- 使用多路复用 IO 模型,非阻塞 IO。
cluster 集群扩容与缩容操作过程。
附录
- redis 中文网。
- 可视化 GUI 推荐 AnotherRedisDesktopManager。
- 超好用的 java redis 框架 redision。